
 爸爸与女儿
爸爸与女儿
作家|王兆洋
“MoE”加上“前所未有大领域过问坐蓐环境的 Lightning Attention”,再加上“从框架到CUDA层面的如软件和工程重构”,会得到什么?
谜底是,一个追平了顶级模子技艺、且把高下文长度进步到400万token级别的新模子。
1月15日,大模子公司MiniMax认真发布了这款预报已久的新模子系列:MiniMax-01。它包括基础讲话大模子MiniMax-Text-01 和在其上集成了一个轻量级ViT模子而蛊卦的视觉多模态大模子 MiniMax-VL-01。
MiniMax-01是一个总参数4560亿,由32个Experts构成的MoE(搀杂民众)模子,在多个主流评测集上,它的空洞技艺与GPT-4o和Claude 3.5 sonnet皆平,而同期,它的高下文长度是今天顶尖模子们的20-32倍,况且跟着输入长度变长,它亦然性能衰减最慢的阿谁模子。
也便是,这但是实打实的400万token高下文。

这对今天系数大模子来说都是个新打破。而MiniMax实现它的时势也很激进——
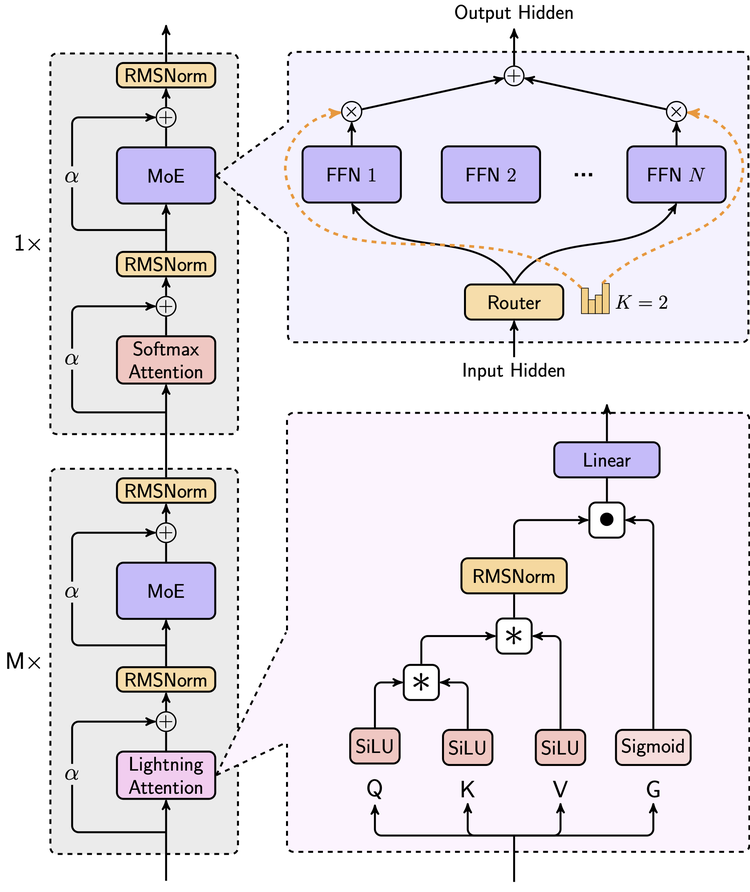
如斯大参数的模子并不有数,但它是第一个依赖线性堤防力机制的大领域部署的模子。在堤防力机制层面,MiniMax-01作念了果敢的转变,在业内初度实现了新的线性堤防力机制,它的80层堤防力层里,每一层softmax attention层前放手了7层线性堤防力lightning attention层。
Softmax attention是Transformer的中枢堤防力机制,它是Transformer成为今天大模子欢乐里的基石的要害,但同期它也有着先天的问题——它会让模子在处理长文本时复杂度成n的闲居的增多。线性堤防力则不错把复杂度限度在线性增多。线性堤防力机制关联的磋议一直在冒出来,但它们时时是一种“实验”的现象,MiniMax-01第一次把它放到了坐蓐环境里。
它的主见便是要在资本得以限度的同期,给MoE模子带来更长的高下文技艺。
“咱们但愿这个模子能为接下来的AI Agent爆发作念出孝顺。”MiniMax-01亦然MiniMax第一个开源的模子,它的权重等一齐对社区公开。

MiniMax是国内最早作念预磨练模子的生意公司之一,在模子的技能路子上它一直按着我方的想法走。而这些路子屡次被说明成为了业内自后的主流标的。MiniMax-01是这家公司的技能品尝和技能路子在今天的一个麇集展示。
它再次把许多东说念主敬佩的实验性身分,一步一步构成它我方信仰的基础模子架构,并用最极致且真刀真枪堆资源的时势实现了出来。
1
敬佩线性堤防力和MoE,修复一个全新模子架构
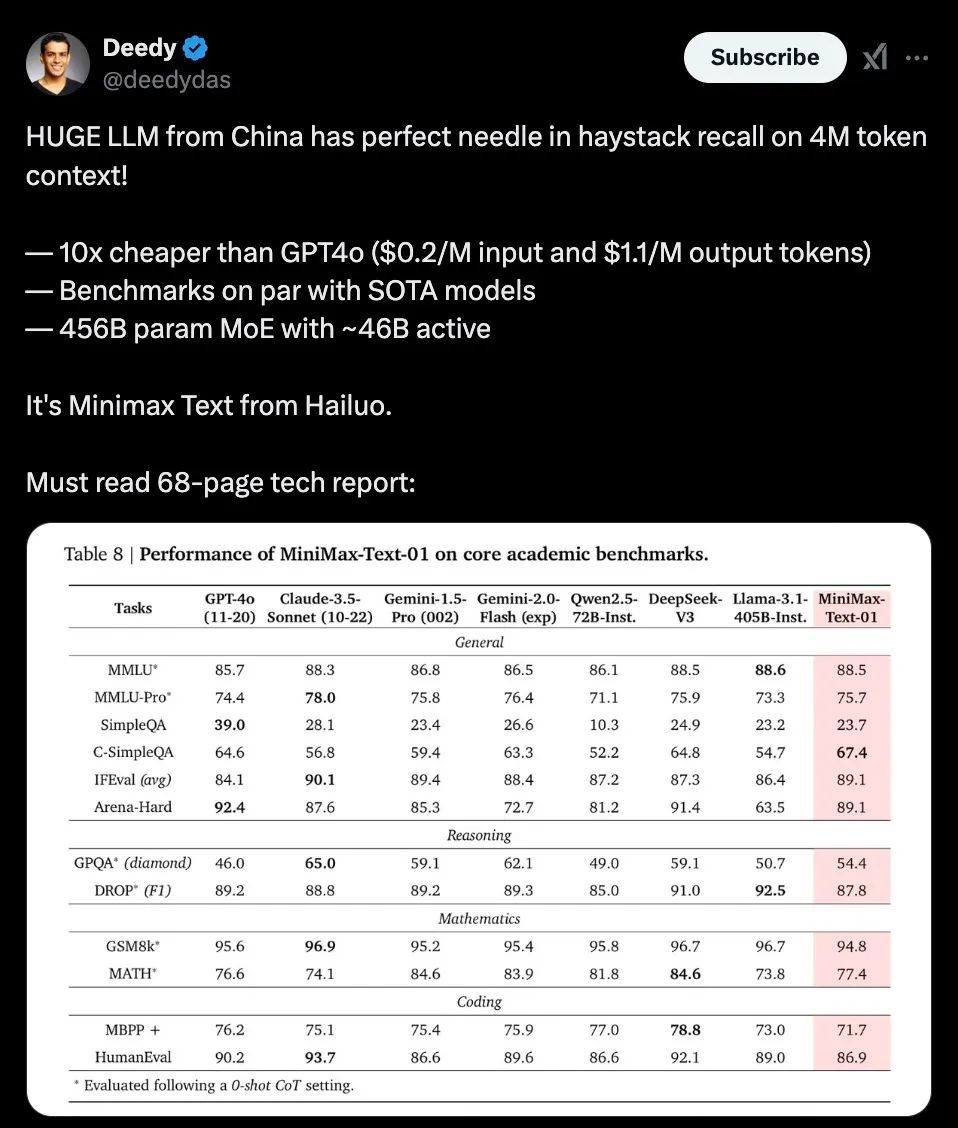
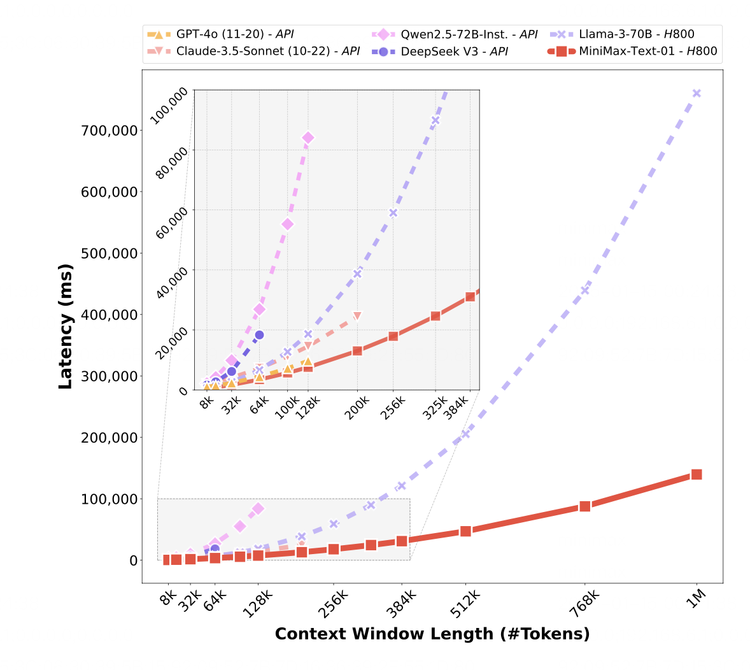
左证这份技能敷陈里提供的评测信息,MiniMax-01在业界主流的文本和多模态理罢免务上的发达,在大多数任务上追平了来自OpenAI和Anthropic的起头进模子,在长文技艺上,它与目下在高下文技艺上最强的Google Gemini对比,自满出更强的富厚性,况且跟着输入文本的增多,评分开动出现显著的起头。
成人熟妇小说在线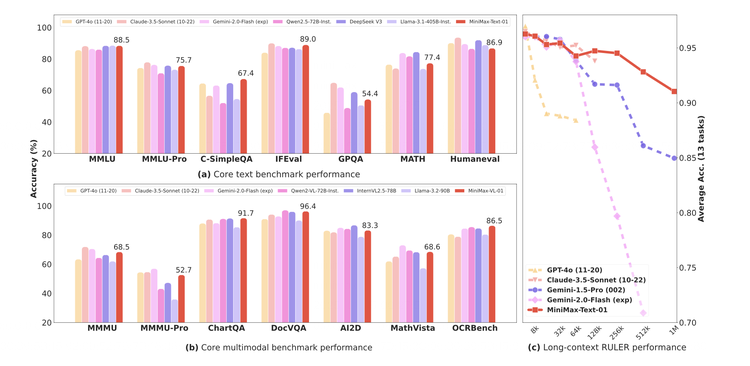
动作同期领有多个明星toC产物的公司,MiniMax也构建了一个基于竟然助手场景数据的测试集,它在其中的发达也呈现出相同的特征,基本技艺在第一梯队,长文本技艺显著起头。
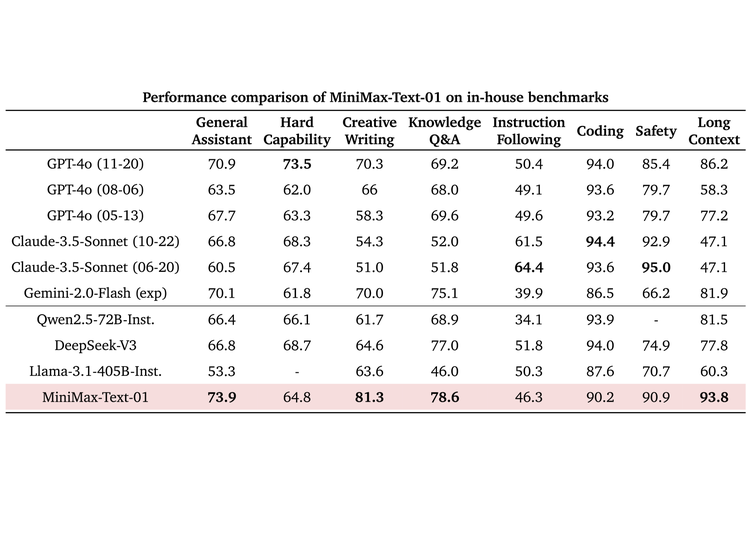
“这个责任的中枢是咱们第一次把线性堤防力机制延长到商用模子的级别,从Scaling Law、与MoE的纠合、结构想象、磨练优化和推理优化层面作念了空洞的接头。由于是业内第一次作念如斯大领域的主要依赖线性堤防力模子,咱们简直重构了咱们的磨练和推理系统,包括更高效的MoE All-to-all通讯优化、更长的序列的优化,以及推线性堤防力层的高效Kernel实现。”MiniMax先容。
这是一个弥远的系统性的责任,从算法到架构再到软硬件训推一体的基础要领,MiniMax的技能品尝和定力基本都体目下了MiniMax-01的转变上。
在前年MiniMax第一次蛊卦者行动上,首创东说念主就曾系整个享过MiniMax的技能“信仰”:更快的磨练和推理,而实现时势他其时也举了两个例子:线性堤防力和MoE。而这次的开源模子技能敷陈基本便是那次共享的“交功课”,它贫乏把MiniMax的诸多责任展示给了外界。
在MoE上,一年前MiniMax认真全量上线了国内第一个千亿参数的MoE模子。简便来说,MoE (Mixture of Experts 搀杂民众模子)架构会把模子参数区分为多组“民众”,每次推理时唯唯一部分民众参与计较。这种架构不错让模子在小参数的情况下把计较变得更精致,然后领有大参数才有的处理复杂任务的技艺。
关于MoE模子来说,配置几个民众、决定民众分派的路由若何优化等,是决定它效用的要害。这次的MiniMax-01,第四色经过各式实验后,细则模子内使用 32 个民众模块,固然总参数目达到了 4560 亿,但每个 token 激活的参数仅为 45.9 亿。这个设定的现实接头,是要让模子在单台机器8 个 GPU 和 640GB 内存的条目下,使用 8 位量化处理跳跃 100 万个token。同期,它还改进了全新的 Expert Tensor Parallel (ETP) 和 Expert Data Parallel (EDP) 架构,它们能匡助裁汰数据在不同民众模块间通讯的资本。
而更中枢便是对堤防力机制的重构。
在MiniMax-01的性能敷陈里有这样一张图,从中不错看到,在其他模子处理256k的时候窗口内,MiniMax的模子不错处理多达 100万个词的信息。也便是说,即使模子一次只可专注于一部天职容,它仍然不错通过高效的计较政策和隐秘的想象,将更多信息纳入举座分解。
把模子想象成在翻阅一册巨大的书,即使每次只可看几页,但它能记着之前的内容,最终把整本书的常识都处理一遍。
关于传统的Transformer来说,它使用Softmax堤防力,需要为此构建一个N×N 的全一语气矩阵,关于超长序列,这个矩阵会相配深广。而 Lightning Attention 这样的线性堤防力机制则是进行“分块计较”(tiling),模子将超长序列分红几许小块,每个块的大小固定,先计较块里面的词之间的接洽(intra-block),接着再通过一种递归更新的秩序,将块与块之间的信息冉冉传递(inter-block),使得最终不错捕捉到全局语义接洽。
这个流程访佛于分组商讨:先惩办每组里面的问题,再汇总系数组的脱色,最终得到全局的谜底。
这种优化大大减少了计较和内存需求,也从传统 Softmax 堤防力的闲居复杂度裁汰为线性。
同期,为了均衡效用与全局信息捕捉技艺,它通过多半的实验最终找到当下搀杂堤防力机制的最好配方:7比1。在 Transformer 的每 8 层中,有 7 层使用 Lightning Attention,高效处理局部接洽;而剩下 1 层保遗留统的 Softmax 堤防力,确保简略捕捉要害的全局高下文。
和传统的机制比拟,一个是看书时候每个字都看,另一个是挑要点看,然后偶尔看一下目次对照一下举座。效用当然不同。
此外,它还引入了Varlen Ring Attention,用来径直将系数这个词文本拼接成一个一语气的序列,从而让变长序列的数据在模子中按需分派资源;在预磨练数据上使用数据打包(Data Packing),将不同长度的文本拼接成一语气的长序列;在漫衍式计较时改进了 Linear Attention Sequence Parallelism (LASP+),使模子简略在多 GPU 之间高效融合,无需对文本进行窗口切分。
某种进程上,MiniMax在引入线性堤防力机制上的“形而上学”,和它一直以来追逐MoE模子路子的念念想是世代相承的——便是用更机灵的时势惩办问题,把资源阐明到极致,然后通过多半真刀真枪的实验把它在竟然场景大领域实现。
线性堤防力和MoE在MiniMax-01这里,成了绝配。
1
下个Transformer时刻
当模子的代际迭代不再凶猛,高下文长度和逻辑推理正在成为两个最要点标的。
在高下文方面,此前Gemini一度是最长的阿谁。而且,DeepMind的CEO Demsi Hassabis曾经披露,在Google里面,Gemini模子依然在实验中实现过1000万token的长度,况且敬佩最终会“抵达无穷长度”,但不容Gemini目下就这样作念的,是它对应的资本。在最近的一个访谈里他暗示,Deepmind目下依然有新的秩序来惩办这个资本难题。
是以,谁能先把高下文长度提高,同期把资本打下来,谁可能就会占得先机。从MiniMax-01展示的成果来看,它的效用照实获取了质的进步。
在这篇详备的技能敷陈里,从一个数据不错看出关于硬件的使用效用——在推理上,MiniMax 在 H20 GPU 上的MFU 达到了 75%。这是一个终点高的数字。
MFU(Machine FLOPs Utilization,机器浮点诳骗率)指的是模子在运行流程中对硬件计较技艺(FLOPs,即每秒浮点运算次数)的实践诳骗率。简便来说,MFU 容貌了一个模子是否充分阐明了硬件性能。高诳骗率必将带来资本上的上风。
MiniMax 01无疑是近来暮气千里千里的“撞墙论”中,贫乏令东说念主惊喜的模子之一。另一个最近激励庸碌商讨的是DeepSeek V3。如上头所说,今天两个过错的标的,一个在推理,一个在更长高下文,Deepseek V3和MiniMax-01 各自代表了其中一个。
专诚义的是,从技能路子上,某种进程上两者都是在对奠定今天茁壮基础的Transformer里最中枢的堤防力机制作念优化,而且是果敢的重构,软硬件一体的重构。DeepSeek V3被描画把Nvidia的卡榨干了,而MiniMax简略实现如斯高的推理MFU,很要害的亦然他们径直对磨练框架和硬件作念优化。
左证MiniMax的敷陈,他们径直我方从零开动一步步深度蛊卦了一个相宜线性堤防力的CUDA 内核,并为此蛊卦了各式配套的框架,来优化 GPU 资源的诳骗效用。两家公司都通过更紧密的软硬纠合技艺实现了打算。
另一个专诚义的不雅察是,这两家出彩的公司,都是在ChatGPT出现之前就依然过问到大模子技能研发里去的公司,这两个模子惊艳之处也都不在于夙昔习尚看到的“追逐GPT4”的模式,而是左证我方对技能演进的判断,作念出的重过问、以致有些赌堤防味的转变,在一系列抓续的塌实责任后,交出的答卷。
而且这答卷也都不仅仅对我方的,它们都在试图说明某些曾停留在实验室的见识,在大领域部署到实践场景里后也不错有它应承的成果,并借此让更多东说念主持续优化下去。
这未免让东说念主空猜度Transformer出现的时候。
当初Attention机制也依然在实验室走红,但争议依然不断,是敬佩它的后劲的Google信得过堆上了算力和资源,把它从表面实验,作念成了大领域部署实现出来的真东西。接下来才有了东说念主们蜂涌而上,沿着被说明的路子走到今天的茁壮。
其时的Transformer把堤防力机制堆了更多层,用上了更多的算力,今天的MiniMax-01则在尝试透顶考订旧的堤防力机制,一切都有些似曾结识。以致其时Google的磋议员为了强调堤防力机制而起的阿谁知名的论文标题“Attention is all you need ”也相配相宜被MiniMax鉴戒:线性堤防力is all you need ——
“模子目下仍有1/8 保留了普通softmax 堤防力。咱们正在磋议更有用的架构,最终十足去掉softmax 堤防力,从而有可能在不出现计较过载的前提下实现无扫尾高下文窗口。”
在这篇论文的临了,MiniMax的磋议员们这样写说念。
这显著是巨大的狡计,但在如今东说念主们都在注庞大模子接下战役哪儿走的时候,相配需要这样的狡计,相配需要一个或者更多个“Transformer时刻”——在一个我方敬佩的路子上作念到极致,把看似系数东说念主都知说念的配方,最终结束出来,展示给技能社区里的东说念主们爸爸与女儿,让它酿成某个决定性的时刻,给AI的前进再添把火。